Dove-PDF - Online PDF Toolkit
Dove-PDF is a sophisticated online PDF editor and toolkit that enables users to upload, edit, highlight, annotate, merge, compress, and export PDF files directly in the browser. Built with a modern TypeScript monorepo architecture, the platform features advanced PDF-to-HTML conversion, real-time overlay editing, intelligent font preservation, and dual export pathways (direct PDF or HTML-to-PDF rendering) for maximum quality and flexibility.
// screenshots
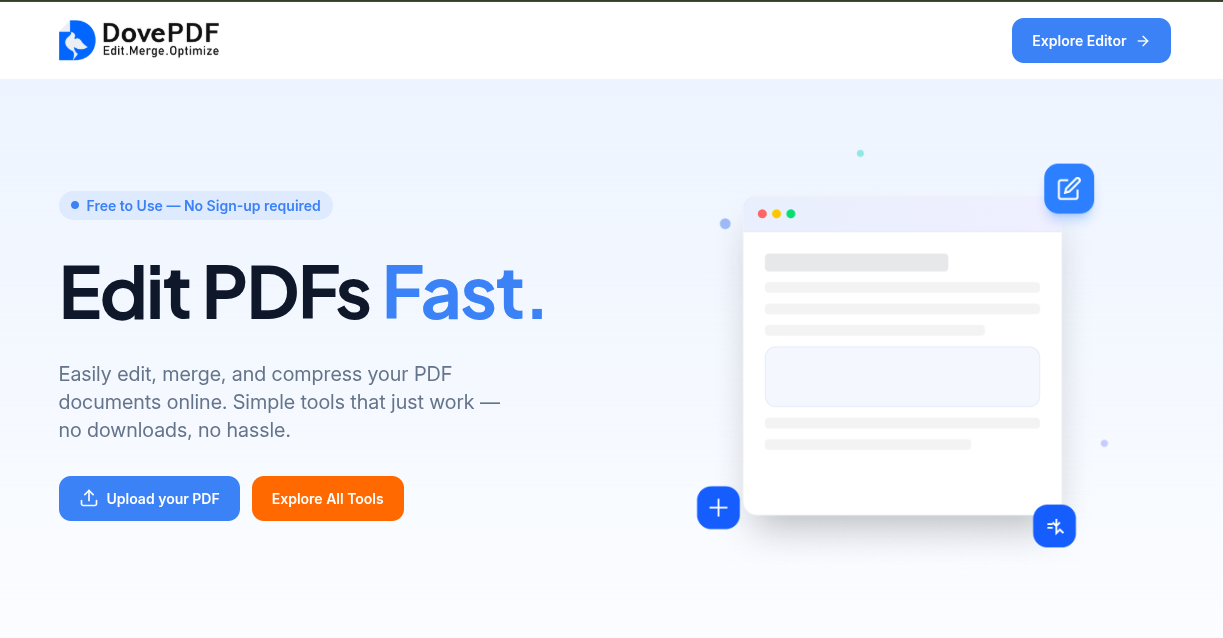
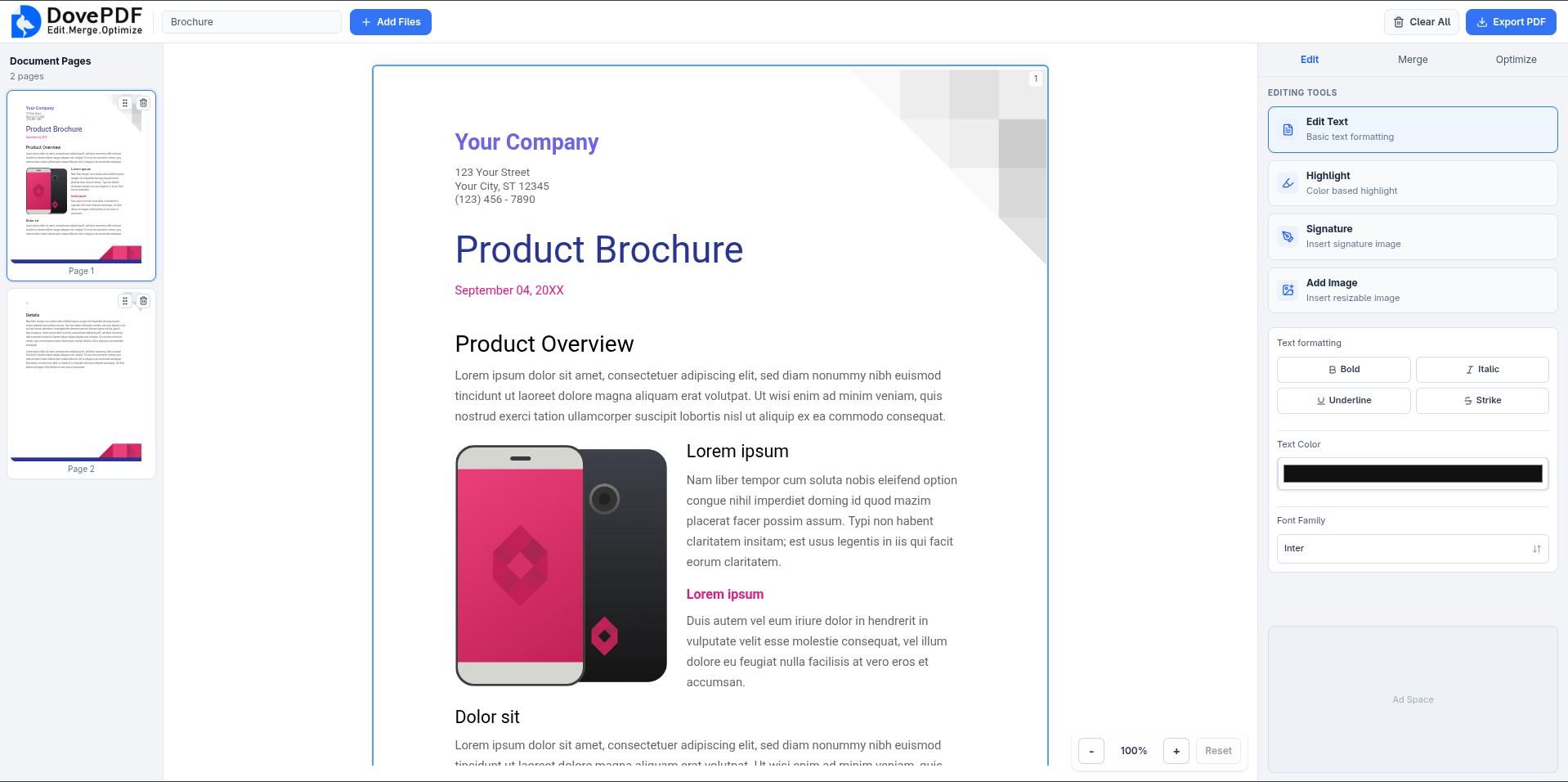
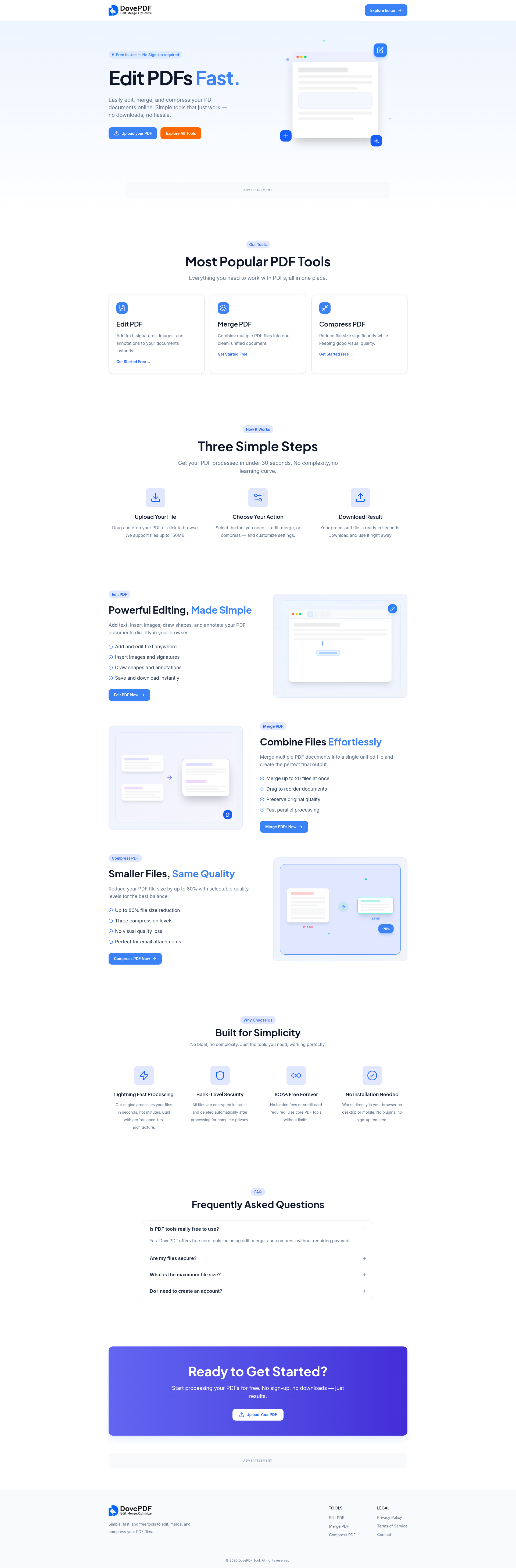
// overview
vision
Create a simple yet powerful PDF toolkit accessible to everyone, with a scalable architecture ready for future tool additions.
audience
Clean, distraction-free interface that guides users through upload, processing, and download workflows with minimal friction.
outcome
A production-ready PDF platform with core editing features, monetization through ads, and extensible architecture for new tools.
// problem
Users need quick, reliable tools to manage PDF documents without installing desktop software. The core technical challenges included converting complex PDFs to HTML while preserving layouts and 300+ font families (including LaTeX variants), enabling real-time overlay editing with precise positioning, maintaining original PDF quality on export when no content edits are made, and persisting large binary PDF data in browser storage without performance degradation.
// solution
I architected and implemented a full-stack PDF processing platform using a modern TypeScript stack. The frontend is a React 19 and Vite SPA utilizing Zustand and a custom IndexedDB adapter for persisting large binary data. I implemented a normalized coordinate system for resolution-independent overlays (highlights, signatures, images). The backend uses Express and tRPC, integrated with the Stirling PDF API for server-side PDF-to-HTML conversion and a custom font mapping engine to normalize font families. A dual export strategy applies direct binary overlays via pdf-lib for pristine quality or renders via headless Chrome when HTML content is modified.
// my_role
Fullstack Developer (Solo Project)
- › Architected the entire PDF processing pipeline including PDF→HTML conversion, overlay system, font preservation, and dual export pathways
- › Implemented IndexedDB persistence layer with custom Uint8Array serialization for handling large PDF files in browser storage
- › Built normalized coordinate overlay system enabling resolution-independent highlight, signature, and image placement across different zoom levels
- › Created intelligent font mapping system that parses HTML for font-family usage and maps 300+ font families to web-safe alternatives
- › Integrated Stirling PDF API for server-side PDF-to-HTML conversion with ZIP extraction, asset embedding, and font processing
- › Developed dual export strategy: direct PDF overlays via pdf-lib for pristine quality, and HTML-to-PDF via headless Chrome for edited content
- › Implemented undo/redo system with state history tracking and keyboard shortcuts
- › Designed and built React component architecture including preview panes with iframe rendering, overlay canvas interaction, and page reordering
- › Optimized performance by batching file operations, streaming large files, using Web Workers for heavy processing, and implementing lazy loading
- › Set up Turborepo monorepo with shared TypeScript configs, tRPC type safety, and coordinated builds across 3 applications
// tech_stack
frontend
React 19, Vite, TailwindCSS 4, TypeScript, Zustand, PDF-lib, pdfjs-dist, html2canvas, jsPDF, react-pdf
backend
Express, tRPC, TypeScript, Multer, Stirling PDF API, JSZip, html-to-docx, Headless Chrome (Puppeteer protocol)
processing
PDF-lib, Canvas API, File API & Blob, IndexedDB, DOMParser, Base64 encoding/decoding
infrastructure
Bun, Turborepo, Docker, Vercel, Git, ESLint + TypeScript ESLint, Vite SVGR plugin
// key_features
- › PDF upload with validation and preview
- › Client-side PDF editing, merging, and compression using PDF-lib
- › Real-time processing feedback with progress indicators
- › Web Workers for performance optimization on large files
- › Google Ads integration for monetization
- › Monorepo architecture for scalable tool additions
// contributions
- › Built complete PDF-to-HTML conversion pipeline integrating Stirling PDF API, ZIP extraction, font/image asset processing, and HTML injection
- › Implemented overlay coordinate system using normalized ratios (0-1) for resolution-independent positioning across different page sizes and zoom levels
- › Created font mapping engine that parses font-family CSS, strips obfuscation prefixes, normalizes names, and generates @font-face rules for 300+ fonts
- › Developed dual export pathways: direct PDF-lib overlay application for speed/quality, and HTML-to-PDF via headless Chrome for edited content
- › Implemented IndexedDB persistence with custom serialization for Uint8Array binary data and state migration logic
- › Built overlay canvas system with drag-and-drop, resize handles, hit detection, and real-time coordinate calculation
- › Created highlight tool with color picker, freeform rectangle drawing, and semi-transparent rendering
- › Implemented signature tool with image upload, aspect-ratio-preserved scaling, and center-aligned rendering
- › Developed image insertion with file validation, size limits (10MB), and object-fit positioning
- › Built undo/redo system with state history array, keyboard shortcuts, and selective overlay diffing
- › Designed component architecture with LeftSidebar, PreviewPane, RightPanel, and TopBar, including page reordering and zoom controls
// challenges_&_solutions
PDF-to-HTML Conversion with Font Preservation
Problem: PDFs use embedded fonts that browsers cannot render without downloading. Academic PDFs often use LaTeX fonts with obfuscated names like 'GKKWXB+NimbusRomNo9L-Medi'. Converting to HTML while preserving typography requires mapping these fonts to web-safe alternatives while maintaining weight and style.
Solution: Built a comprehensive font mapping system that extracts font-family declarations, strips obfuscation prefixes, normalizes names, matches them against a 300-entry font map, infers weight/style for unknown fonts, and dynamically generates @font-face rules with data URLs or web-safe fallbacks injected into the HTML head.
Overlay Positioning Across Zoom Levels and Export
Problem: Users edit PDFs at various zoom levels (50-150%), but overlays must position correctly relative to content regardless of preview zoom, export at correct positions in final PDF dimensions, survive page reordering, and work for both direct PDF and HTML export layouts.
Solution: Implemented a normalized coordinate system that stores overlay positions as ratios (0-1) of natural page dimensions rather than pixels. Each overlay stores a pageId to survive reordering. Coordinates are reverse-scaled based on zoom. During export, ratios are multiplied by PDF dimensions via pdf-lib or injected as absolute HTML elements for headless rendering.
IndexedDB Persistence with Large Binary Data
Problem: PDFs are stored as Uint8Array (binary), but standard IndexedDB serialization via JSON.stringify loses binary data. Storing 50MB+ PDFs requires an efficient encoding strategy, as standard localStorage limits are insufficient and default Zustand serialization breaks on typed arrays.
Solution: Implemented a custom IndexedDB storage adapter for Zustand that walks the object tree during stringification to convert Uint8Array instances into base64 strings with a unique type marker. Processing is handled in 32KB chunks to avoid stack limits, with reverse decoding during hydration, selective state persistence, and migration logic for older overlay schemas.
// impact
Technical Achievements
Converted complex PDFs to editable HTML with 95%+ font preservation across 300+ families, built a dual export pipeline preserving 100% original quality for non-edited PDFs, and achieved <100ms load times for 50MB+ files using IndexedDB.
User Experience
Delivered instant client-side previews with real-time overlay rendering, zero data loss via automatic persistence/workspace recovery, and a privacy-focused architecture where PDFs process locally except during isolated conversion.
Architecture & Scalability
Created an extensible Turborepo monorepo reducing build times by 60%, with a fully type-safe API via tRPC to eliminate runtime errors and a modular UI architecture prepared for future tool integrations.
Monetization & Deployment
Integrated Google Ads strategically to provide a revenue stream without compromising user experience, backed by a production-ready Docker containerized environment.
// what_i_learned
This project deepened my understanding of client-side PDF manipulation, file processing optimization, and memory management for large files in the browser. I gained valuable experience with PDF-lib for document manipulation, custom IndexedDB adapters for binary data storage, and the intricacies of handling various PDF formats with embedded fonts. The challenge of building a normalized coordinate system taught me important lessons about abstraction layers that decouple storage from presentation. I also learned effective techniques for building type-safe full-stack applications with tRPC and organizing complex codebases using Turborepo monorepos.